
학습에서의 상호운용성(interoperability)은 개인이 삶의 모든 과정에서 접하게 되는 학습 환경, 시스템, 데이터, 조직적 요소를 아우르는 개념입니다. 이동성이 높은 현대 사회에서는 학습과 관련된 정보가 효율적으로 공유되는 것이 필수적입니다. 개인이 경력을 발전시키거나, 한 경력에서 다른 경력으로 전환하거나, 혹은 여러 조직에서의 학습 단계를 거쳐가는 동안, 이들의 학습 경험에 대한 고품질 데이터가 원활히 공유될 필요가 있습니다.
하지만 현재의 학습 생태계는 서로 독립적으로 운영되는 조직들과 높은 수준으로 맞춤화된 관리 시스템, 그리고 일관성이 부족한 다양한 데이터 아키텍처들로 이루어져 있습니다. 이러한 상황에서는 서로 다른 벤더들이 제작한 다양한 제품과 시스템에서 데이터를 교환하는 것이 쉽지 않습니다. 미래의 학습 생태계를 실현하기 위해서는 평생학습의 전 과정을 통합할 수 있는 데이터 교환이 필수적입니다. 이를 가능하게 하는 핵심 요소가 바로 국제적으로 인정받는 기술 사양과 표준을 기반으로 한 상호운용성입니다.
오늘날의 디지털 세상에서는 정보가 어디서나 쉽게 접근 가능합니다. 대규모 소셜 네트워크, 상호작용형 콘텐츠, 그리고 어디서든 접속 가능한 모바일 기술은 교육과 훈련에서 중요한 혁신 기술로 부상하고 있습니다. 동시에, 데이터 과학은 학습 콘텐츠의 효과성을 평가하고, 대규모 학습 데이터를 통해 조직적 경향을 이해하며, 수집된 데이터를 활용해 교육과 훈련을 지속적으로 개선할 수 있는 새로운 기회를 제공합니다.
그럼에도 불구하고, 상호운용성에는 여전히 도전 과제가 존재합니다. 현재의 디지털 학습 생태계는 단편화되어 있어, 하나의 시스템에서 생성된 데이터를 다른 시스템에서 통합하거나 활용하기가 어렵습니다. 이로 인해 학습 기록은 기관 간이나 조직 간에 쉽게 전송되지 못합니다. 더욱이, 각 교육 및 훈련 기관은 학습자의 활동이나 성과 정보를 기록하는 방식이 제각각이며, 이 데이터 형식조차 표준화되어 있지 않아 데이터를 통합하고 분석하는 과정이 더욱 복잡해지고 있습니다.
FORMAL LEARNING PROGRESSION: 공식 학습의 발전
K–12 교육부터 시작해 대부분의 주(州) 교육 시스템은 여러 벤더의 제품을 사용하고 있으며, 각 학군은 독립적으로 시스템을 운영합니다. 기존의 이러한 애플리케이션들은 표준화된 데이터 기반을 거의 사용하지 않았거나 전혀 사용하지 않았습니다. 대신, 대부분 각자 고유의 내부 데이터 모델을 사용해왔고, 시스템 간 통합은 주 또는 지역 차원에서 복잡한 임시 연결 방식에 의존해야 했습니다. 그 결과, 서로 다른 애플리케이션 간의 통합에는 여전히 많은 간극이 존재하며, 많은 시스템이 상호운용성을 갖추지 못한 상황입니다.
이상적으로는, 학습 관리 시스템(LMS), 학생 정보 시스템(SIS), 학습 객체 저장소(LOR) 같은 여러 제품에서 생성된 데이터가 공통 데이터 표준에 맞춰 정렬되어야 합니다. 이렇게 되면 이러한 애플리케이션 간의 원활한 연계와 조정이 가능해질 것입니다.
가장 큰 문제는 고등교육 학습 시스템 전반에 걸쳐 연결된 인프라가 부족하다는 점입니다.
– 앰버 개리슨 던컨 박사, 루미나 재단 전략 디렉터
고등교육 시스템 역시 독립적으로 운영되는 구조입니다. 학점 중심의 운영, 학기 단위의 과정, 공식 자격 인증에 초점을 맞추는 기존의 시스템은 디지털화되고 글로벌로 연결된 세계에서 가능해진 새로운 학습 방식들을 충분히 반영하지 못하고 있습니다. 예를 들어, 점차 주목받고 있는 글로벌 온라인 학습 환경은 공식 학습과 비공식 학습의 경계를 허물고 있습니다. 이제 학생들은 더 상호작용적이고 자기주도적인 학습 방식에 관심을 두고 있으며, 온라인에서 방대한 정보(심지어 무료로 제공되는 경우도 많음)를 쉽게 찾을 수 있게 되면서, 대학이 더 이상 고등교육의 유일한 선택지가 아니게 되었습니다. 이로 인해, 학위의 가치는 점점 감소하고 있으며, 고용주들은 점점 더 공식 교육 외부에서 개발된 실질적인 역량을 중요하게 평가하고 있습니다.
군 교육 및 훈련에서도 마찬가지로 다양한 학교와 프로그램이 운영되며, 이들은 주로 기술, 전문성, 리더십 역량을 육성하는 데 초점을 맞추고 있습니다. 하지만 이러한 프로그램, 교육 기술, 인사 정보 시스템들 역시 각각 독립적으로 운영되는 구조를 가지고 있습니다. 게다가, 미국 국방부 내에서는 교육과 훈련 커뮤니티 간의 분리가 오래전부터 이어져 왔습니다.
전통적으로, 교육은 점진적으로 진행되며, 학습 개념에 대해 고민하고 반추하면서 불확실성을 다루는 과정을 포함합니다. 반면, 훈련은 즉각적인 피드백과 진행 상황 측정이 가능한 방식으로 지식, 기술, 능력을 적용하며, 실질적인 준비 상태를 높이는 데 초점이 맞춰져 있습니다. 현재의 환경에서는 교육과 훈련이 각기 다른 보고 체계, 동기, 그리고 연료, 인력, 적절한 환경 또는 장비에 대한 접근 등과 같은 물류 요구사항을 가지고 있습니다. 이로 인해, 다양한 출처에서 데이터를 수집하더라도 이 데이터들이 표준화되거나 연결되지 못하는 경우가 대부분입니다.
상호운용성의 유형
현대 교육과 훈련의 환경에서는 빠른 기술 변화가 일상이 되었습니다. 이러한 변화는 교육자, 훈련자, 행정가, 그리고 학습자 모두에게 큰 압박으로 다가옵니다.
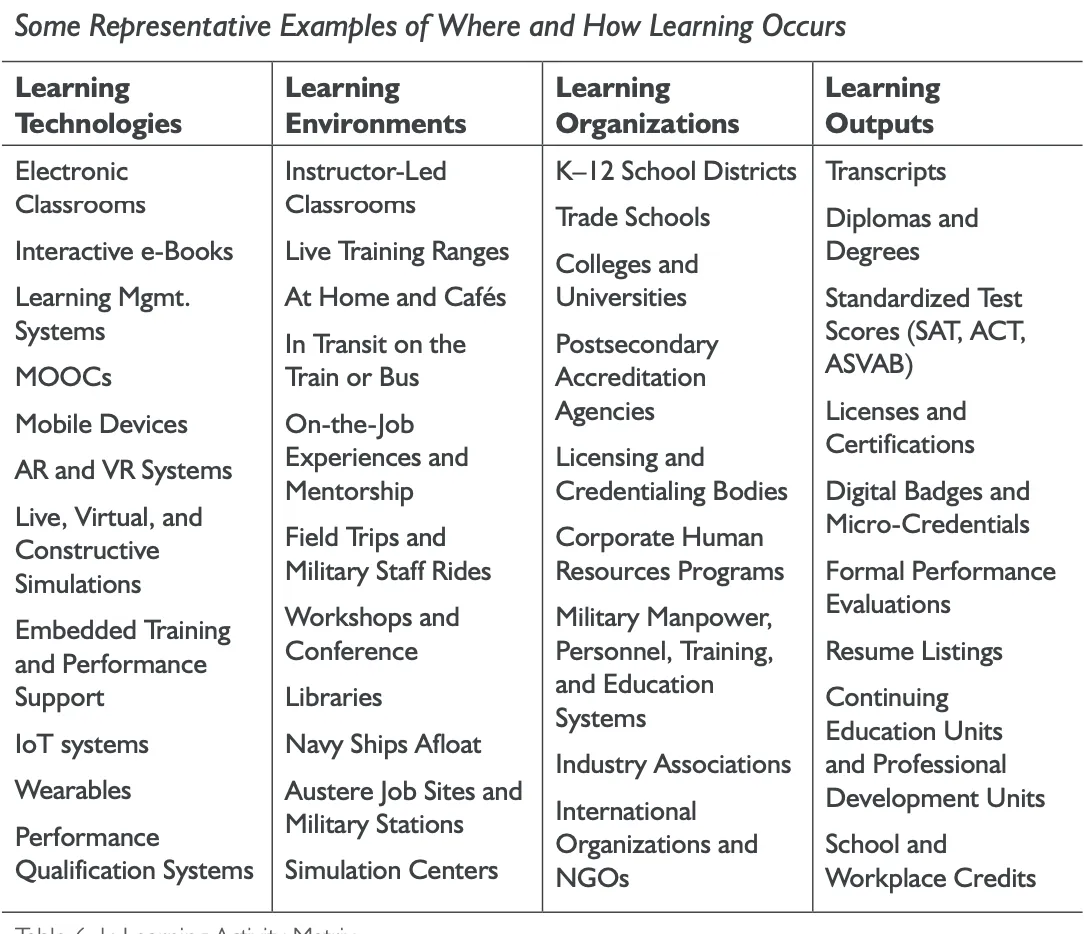
표 6-1은 학습자가 경력 전반에 걸쳐 접하게 될 다양한 학습 기술, 환경, 조직, 그리고 학습 결과들을 다른 시각으로 보여줍니다. 이 매트릭스는 미래 학습 경제를 실현하기 위해 필요한 여러 유형의 상호운용성(interoperability)을 강조합니다. 이는 현재의 학습 환경에서 나타나는 조직적 구조와, 훈련과 교육이 이루어지는 시점과 장소에 따라 달라지는 보고 체계와 책임의 차이에서 비롯된 것입니다.
상호운용성의 여러 유형
► 시스템 상호운용성 – 디지털 시스템은 서로 협력해야 합니다. 현재 데이터를 수집, 관리, 분석, 보고하는 데 사용하는 기존 시스템은 종종 서로 연결되어 있지 않으며, 항상 잘 작동하지 않습니다. 기술적 과제 중 일부는 데이터 표준의 불일치와 데이터를 활용 가능한 형식으로 접근할 수 없는 문제를 포함합니다. 정부, 산업, 학계 전반에서 여러 노력을 통해 점진적으로 개선이 이루어지고 있습니다.
► 애플리케이션 상호운용성 – 시스템은 여러 개의 분리된 애플리케이션으로 구성되어 있으며, 이 애플리케이션들은 이론적으로 개별 학습자에게 학습에 어떤 영향을 미치는지에 대해 모두 소통할 수 있어야 합니다. 그러나 현재는 애플리케이션마다 성과를 추적하는 방식이 다르며, 애플리케이션 내 개별 활동에 대한 정보를 해석하는 능력도 항상 명확하지 않습니다.
► 데이터 상호운용성 – 애플리케이션 간 데이터의 원활하고, 안전하며, 통제된 교환은 개인 학습을 이해하는 능력을 최대화하는 데 중요합니다. 그러나 데이터는 종종 애플리케이션 내에 고립된 상태로 저장되며, 이러한 데이터 세트는 종종 맞춤형 또는 독점 데이터 모델을 사용합니다. 상호운용 가능한 애플리케이션에 대한 투자 효과를 극대화하고, 인력 계획을 수행하며, 데이터 분석으로 얻을 수 있는 이점을 지원하기 위해서는 공통 데이터 표준, 데이터 거버넌스 및 메타데이터 정보가 필요합니다.
► 인간-기계 상호운용성 – 학습이 이루어지는 다양한 환경은 사용하는 학습 기술의 유형에 영향을 미칩니다. 새로운 도구와 기술이 등장함에 따라 개인은 점점 더 기술적으로 숙련되어야 하며, 산업은 다양한 컴퓨팅 플랫폼, 기기, 학습 양식 간에 학습의 원활한 전환을 지원할 방법을 찾아야 합니다.
► 조직 상호운용성 – 데이터 소유권은 진정한 상호운용성을 방해하는 중요한 장애 요소입니다. 지식 경제에서는 데이터가 종종 학습 이외의 목적으로 수익화되거나 활용됩니다. 조직뿐만 아니라 데이터에 민감한 개인들 역시 데이터를 공유하는 데 주저합니다. 플랫폼 간 및 조직 간 상호운용성을 구축하려면 문화적 변화가 필요하며, 이는 기술적 상호운용성보다 더 어려운 도전 과제가 될 수 있습니다.
현재 교육 기관, 훈련 조직, 그리고 교수 기술은 학습자 데이터의 일부를 수집하고 있습니다. 예를 들어, 인구통계학적 정보, 평가 결과, 교사의 관찰, 학습자가 생성한 콘텐츠, 출석률, 그리고 성적 등이 포함됩니다. 하지만 이러한 데이터만으로는 학습자가 가진 전반적인 모습을 완전히 파악할 수 없습니다. 이를 위해서는 학습의 전 과정에서 수집된 데이터가 연결되어야 합니다.
더불어, 우리는 일상생활 속에서 다양한 비공식적인 상호작용을 통해 폭넓게 학습에 영향을 받습니다. 이는 다른 사람들과의 상호작용을 통해서나, 스스로 주도하는 학습 활동을 통해 이루어지지만, 이 과정에서 생성된 데이터는 집계, 비교, 분석이 가능한 방식으로 기록되지 않습니다.
이러한 상호운용성 문제를 해결하는 것은 학습자가 지속적으로 업데이트하고, 새로운 기술을 습득하며, 사고를 전환하고, 다시 학습할 수 있는 글로벌 학습 경제(global learning economy)의 기초를 세우는 데 핵심적인 역할을 합니다.
비전 (VISION)
공통 표준과 공유된 기술 사양은 기술적 상호운용성 관점에서 미래 학습 생태계를 위해 필요한 기반을 제공합니다. 이러한 표준은 연결된 구성 요소 간의 상호운용성을 촉진하기 위해 설계된 주요 인터페이스 사양, 통신 프로토콜, 데이터 구조를 규정하는 공표된 문서들로 이루어져 있습니다. 이 문맥에서 상호운용성 사양은 학습자, 활동 및 경험에 관한 데이터를 교환할 수 있도록 하는 일관된 프로토콜을 수립하여, 학습 생태계의 모든 구성 요소가 이를 보편적으로 이해하고 채택할 수 있도록 하는 평생 학습의 기본 구성 요소를 형성합니다.
구글과 교차 도메인 작업의 이점을 사람들이 더 많이 이해할수록 그것을 더 원하게 되며, 동시에 고립된 사일로 구조는 더욱 큰 문제가 됩니다.
Jeanne Kitchens
Chair of the Technical Advisory Committee
for Credential Engine; Associate
Director of the Center for Workforce
Development, Southern Illinois University
미래에는 이러한 상호운용성이 학습자와 학습 활동에 관한 풍부한 데이터를 활용할 수 있게 해줌으로써, 조직이 특정 인구집단의 요구를 충족하는 포괄적인 솔루션을 구축할 수 있게 될 것입니다. 표준화되고 문서화된 인터페이스는 새로운 기능이나 업그레이드된 기능을 기존 플랫폼에 “플러그 앤 플레이” 방식으로 교체하거나 추가할 수 있도록 해줍니다. 다시 말해, 상호운용성은 조직이 다양한 학습 기술(다른 공급업체에서 제공된)을 전체 수명 주기 동안 추가, 수정, 교체, 제거 및 지원할 수 있도록 합니다.
상호운용성은 학습의 연속성에 걸쳐 데이터 집계를 용이하게 합니다. 그리고 이 데이터 분석은 학습자가 자신의 다양한 학습 활동을 통해, 경력 전반에 걸쳐, 궁극적으로는 평생에 걸쳐 학습 여정을 최적화할 수 있도록 해줍니다. 이러한 데이터는 또한 기관 차원의 질문, 예를 들어 어떤 학문 과정이 가장 좋은 학습 결과를 만들어내는지 또는 직업 기술 격차를 예측하는 데 도움을 줄 수 있습니다.
인적 자본 관리 과학과 결합되면, 기업 학습 분석(enterprise learning analytics)은 조직이 승계 계획, 경력 평가 및 성장, 직원 개발, 유지, 지식 공유 등을 포함하는 전략적 인재 관리 목표를 해결하는 데 도움을 줄 수 있습니다.
이 비전을 실현하기 위해서는 여러 유형의 기술적 상호운용성이 필요합니다. 여기에는 학습 및 성과 맥락에서 사용하기 위한 역량을 정의하는 표준화된 방법, 개인의 성과 및 행동에 대한 데이터를 인코딩하는 방법, 이러한 성과 데이터를 의미 있는 방식으로 집계하고 시각화하는 방법, 그리고 다양한 학습 활동을 설명하고 위치를 지정하는 방법 등이 포함됩니다. 다음 하위 섹션에서는 이러한 각각의 내용을 더 자세히 설명합니다.
역량 : 미래 학습 생태계의 “공통 화폐”를 구성하는 상호운용 가능한 프레임워크
역량은 미래 학습 생태계에서 상호운용성의 중심 역할을 하며, 서로 다른 학습 시스템과 인력 응용 프로그램 간의 로제타 스톤 역할을 합니다. 역량(Competency)은 특정 작업을 수행하는 데 필요한 기술, 지식, 능력, 속성, 경험, 성격 특성, 동기를 설명합니다. 역량에는 기술적, 비즈니스, 리더십, 사회적, 윤리적, 감정적 역량 또는 기타 여러 개인적 특성과 능력이 포함될 수 있습니다.
또한, 역량은 사용 맥락에 크게 의존할 수 있습니다. 환경적 요인, 작업의 복잡성, 관련 프로세스나 정책의 차이는 역량의 적용 방식에 영향을 미칠 수 있습니다.
역량 모델(Competency Model) 또는 역량 프레임워크(Competency Framework)는 여러 역량과 그 기본 요소를 결합하여 특정 도메인, 경력, 직무 영역과 관련된 프레임워크를 만듭니다. 일부 역량 모델은 이를 숙련 수준(Levels of Mastery)으로 나누어, 직업 수준별로 필요한 역량 수준에 대한 정보를 제공합니다. 이와 같이 역량 프레임워크 내의 다양한 요소들은 독립적이지 않은(nonexclusive) 관계를 가질 수 있습니다.
교육 및 훈련 기관은 이러한 프레임워크를 활용해 학습 결과를 정의할 수 있으며, 이는 비즈니스 분야에서도 직무 수행과 관련된 하드 스킬(hard skills)과 소프트 스킬(soft skills)의 요구 사항을 정의하고 평가하는 데 널리 사용됩니다. 공통 역량 프레임워크를 사용하면 서로 다른 출처의 데이터를 의미 있게 해석하고, 이를 다른 맥락에 번역할 수 있습니다.
그러나 역량에 대한 표준 부족은 하나의 도전 과제입니다. 다양한 산업, 인증 기관, 무역 협회는 각기 다른 기존 프레임워크를 사용하며, 일부는 여러 사양(specifications)을 따르거나 전혀 따르지 않는 경우도 있습니다. 많은 역량 프레임워크는 루브릭(rubrics), 성과 수준(performance levels), 또는 숙련도를 평가하는 데이터를 포함하고 있지만, 일부는 평가 기준을 보유한 보조적인 외부 요소에 의존하기도 합니다.
일부 역량은 역량이 표현되는 환경에 따라 연결되며, 다른 역량은 교육 또는 훈련 목표(예: 지식, 기술, 능력)에 의해 동기부여됩니다. 미래 학습 생태계 비전을 실현하려면 공통된 용어, 분류 체계, 그리고 역량 프레임워크가 필요하며, 이는 다양한 조직에서 역량 객체와 그 기술자(Descriptors)를 공통적으로 사용하고 재사용할 수 있도록 해야 합니다.
또한, 공유 메타데이터 어휘가 필요할 수 있습니다. 여기에는 포함된 기술 유형(예: 심리운동 기술 또는 인지 기술), 기술 퇴화 추정치(Skill Decay Estimates), 또는 역량의 설명에 영향을 미치거나 정보를 제공하는 환경적 요인과 같은 기술자가 포함될 수 있습니다.
활동 추적 : 학습자의 성과와 행동에 관한 데이터
활동 스트림(Activity Streams)은 우리가 매일 사용하는 많은 애플리케이션에서 거의 보편적으로 사용되는 기능입니다. 예를 들어, 소셜 미디어의 뉴스피드는 사용자의 상호작용을 기록하기 위해 활동 스트림을 사용합니다. 활동 스트림은 행동에 대한 진술로 구성된 순차적 데이터(serialized data)를 활용합니다. 이러한 진술은 일반적으로 주체(활동을 수행하는 사람), 동사(활동의 내용), 그리고 직접 객체(활동이 수행되는 대상 또는 도구)를 포함합니다. 선택적으로, 성과 맥락을 설명하는 다른 요소도 추가될 수 있습니다. 결과적으로 생성된 데이터 세트는 사람이 특정 활동을 수행하는 스토리를 제공합니다.
예를 들어:
• “Mike가 사진을 자신의 앨범에 게시했습니다.”
• “Emily가 영상을 공유했습니다.”
대부분의 경우, 이러한 구성 요소는 명시적이지만, 암시적일 수도 있습니다.
Amber Garrison Duncan, Ph.D., Strategy Director, Lumina Foundation
The T3 Innovation Network is an initiative of the U.S. Chamber of Commerce
Foundation for exploring emerging technologies and standards in the talent
marketplace to better align student, workforce, and credentialing data.
미래 학습 생태계에서는 활동 스트림이 개인이 무엇을 하고 있는지, 어떤 학습 활동을 수행하는지, 그리고 어떻게 수행하는지를 캡처해야 합니다. 스트림의 각 항목에는 타임스탬프가 포함되어야 하며, 이를 통해 학습자의 진행 상황을 상태가 아닌 시간의 함수로 측정할 수 있습니다. 활동 스트림의 목표는 사람이 이해하기 쉬운 형태로, 동시에 기계가 처리하고 확장 가능한 형식으로 활동에 대한 데이터(및 메타데이터)를 제공하는 것입니다.
이 상호작용 데이터는 학습자가 참여하는 모든 활동에 의해 생성되어야 합니다.
• 일부 경우에는 학습자의 성과가 데이터를 생성할 수 있고,
• 다른 경우에는 시스템 이벤트나 학습자가 달성한 중요한 이정표에 따라 시스템이 데이터를 생성할 수 있습니다.
• 또 다른 경우에는 학습자, 애플리케이션, 또는 학습 생태계 내 다른 구성 요소의 맥락을 설정하기 위해 데이터가 생성될 수 있습니다.
활동의 주체(subject)는 거의 항상 학습자이지만, 예측 가능한 상황에서는 교사, 학습 집단(cohort), 또는 다른 인간/기계 에이전트일 수도 있습니다.
활동의 직접 객체(object)는 맥락에 따라 달라지며, 동사 또한 약간의 차이가 있을 수 있습니다.
따라서 시스템 간 데이터의 의미적 상호운용성(semantic interoperability)을 보장하기 위해 동사와 같은 보편적 용어는 공통된 어휘를 사용해야 합니다. 그렇지 않으면 데이터의 유용성이 크게 감소합니다.
공통 어휘를 공식화함으로써, 활동은 학습 생태계 구성 요소가 데이터 세트를 저장하고 검색하는 데 사용하는 속성과 규칙의 설정된 집합을 참조할 수 있습니다.
보편적 학습자 프로파일 : 학습자의 데이터를 통합하고 시각화할 공통된 플랫폼
현재의 학습자 기록 관리 방식은 교사, 학습자, 조직의 진화하는 요구를 충족하기에 충분하지 않습니다. 오늘날 일반적으로 사용되는 성적 증명서는 학습자의 영구적인 학업 기록을 보관하는 데 사용됩니다. 성적 증명서에는 주로 이수한 과정, 받은 성적, 달성한 명예, 수여받은 학위와 같은 기본 정보만이 포함됩니다. 이러한 정보만이 학습자가 다양한 학습 경험을 거치는 동안 그들과 함께 이동합니다.
그러나 교사와 훈련자는 학습자의 과거 성과에 대해, 예를 들어 다른 교사들이 기록한 내용, 학습자가 경험한 비공식적 또는 비형식적 학습, 그들의 강점, 약점, 개인적 요구 사항 등에 대해 거의 가시성을 가지지 못합니다.
변화는 우리가 이를 주도하든 아니든 이미 일어나고 있기 때문에, 진화는 필수적입니다. 사회가 혁신에 요구하는 것들은 우리가 오늘의 시각으로 바라보는 것을 멈추고, 내일의 시각으로 바라보며 K-12 교육에 대한 비전을 세워야 한다는 것을 의미합니다. 오늘의 아이들이 내일의 노동자, 리더, 학자, 또는 군인이 될 것이기 때문입니다.따라서 우리가 던져야 할 질문은 다음과 같습니다:
• 기술을 교육학적으로 어떻게 활용할 수 있을까?
• 단순히 종합 평가(summative assessment)가 아니라, 학습의 개별적인 측면을 형성적으로 평가하여 학습자에게 지금까지 받지 못했던 더 나은 교육을 제공할 수 있을까?
현재 우리의 학업 기준은 기계가 읽을 수 있는 형식(machine-readable format)으로 전환되었으며, 이를 통해 진정한 격차 분석(gap analysis)을 수행하고 교사의 의사 결정을 돕는 추론을 할 수 있습니다. 또한, 이를 통해 수십억 달러의 비용을 절감할 수 있습니다.
- 배지(badge)와 같은 정보가 풍부한 마이크로 인증(micro-credential)은 학습의 진행, 과정, 증거를 측정 가능하게 지원합니다. xAPI를 사용하여 이러한 단계를 기록하면, 학습 기록이 기관 차원을 넘어선 지속적인 문서화로 이어집니다. 이는 평생 인재 관리(lifelong talent-management)를 지원하고, 우리의 시스템이 시간과 공동체를 초월하여 원활하게 정렬될 수 있도록 합니다. 우리가 사용하는 측정 방식이 오늘날에도 유용하며, 다음 공동체에서도 이해 가능해야 합니다.
학습은 실제로 측정 가능합니다.
미래의 학습 기록, 또는 “학습자 프로파일(Learner Profiles)”은 현재의 정규 학습 정보뿐만 아니라, 보다 폭넓은 자격증, 마이크로 인증, 기타 학습 활동 정보를 통합하도록 확장되어야 합니다. 이 프로파일은 단순히 정적인 기록에서 벗어나, 학습자와 조직이 학습자가 원하는 모든 역량을 달성하기 위한 독특한 경로를 결정할 수 있도록 돕는 동적인 도구로 변모해야 합니다.
학습자 프로파일은 더 나은 데이터를 제공함으로써 미래 학습 생태계에서 개인화된 학습을 가능하게 할 잠재력을 가지고 있습니다. 이 프로파일은 다양한 출처에서 수집된 데이터로 구성되며, 명시적 데이터와 유추된 데이터를 모두 포함합니다.
미래의 학습자 프로파일에는 다음과 같은 폭넓은 정보가 포함될 수 있습니다:
• 인구 통계 데이터,
• 개인의 관심사 및 선호도,
• 기존 역량 및 추가로 개발해야 할 역량(개인, 학업, 직업 영역에서),
• 학습자의 강점과 필요,
• 과거에 효과적이었던 학습 개입 방법.
“보편적(universal)“이라는 용어는 학습자 프로파일이 다양한 시스템의 데이터를 통합해 공유된 표현을 구성하는 것을 목표로 하기 때문입니다. 더 나아가, 학습자의 관심사가 변화하거나 새로운 영역에서 역량을 갖추게 되면, 이 프로파일은 최신 상태를 반영하도록 지속적으로 업데이트됩니다.
학습자의 데이터를 보호하고 개인정보를 보존하는 것은 중요한 법적 및 윤리적 고려사항입니다. 학습자가 자신의 데이터를 통제할 필요도 있을 것입니다. 이를 통해 학습자가 자신의 데이터를 획득, 공유, 상호작용할 수 있을 뿐 아니라, 다른 사람, 조직, 또는 애플리케이션이 해당 데이터에 접근할 수 있는 권한을 직접 제어할 수 있어야 합니다.
활동 레지스트리 : 다양한 학습 활동 배열
활동 레지스트리(Activity Registry)는 사용 가능한 학습 자원에 대한 데이터를 수집, 연결, 공유하기 위한 접근 방식입니다. 연합된 저장소(federated repositories), 검색 엔진, 포털과는 달리, 활동 레지스트리는 누구나 학습 자원 및 그 자원의 사용 방법에 대한 정보를 등록, 노출, 소비할 수 있도록 지원하는 자원 배포 네트워크(Resource Distribution Network)입니다. 이 네트워크는 오픈 API를 통해 운영됩니다.
이런 상황에서 훈련에 있어 혁신적 사고(disruptive thinking)를 할 수 있는 능력이 매우 중요하며, 더 나아가 상호운용성(interoperability)을 확보하는 것이 결정적입니다.
주요 기능으로는 다음이 포함됩니다:
• 콘텐츠 메타데이터 생성 및 관리(출판사, 위치, 콘텐츠 영역, 표준 정렬, 평점, 리뷰 등과 같은 데이터)
• 분류체계 및 온톨로지 관리
• 콘텐츠와 역량(competencies) 간의 정렬 관리
• 파라데이터(paradata) 생성 및 관리(자원 사용 데이터, 댓글, 순위, 평점 등 메타데이터에 대한 데이터)
• 의미 기반 검색 서비스 제공
• AI 기반 추천 시스템을 위한 기계가 처리 가능한 메타데이터 생성
활동 레지스트리는 메타데이터, 파라데이터, 진술(assertions), 분석 데이터, 신원 및 평판 정보를 포함하며, 이러한 정보가 배포 네트워크를 통해 흐릅니다. 또한, 학습자에 따른 접근 정보와 권한도 포함합니다. 활동 레지스트리는 다양한 학습 관련 활동 및 런치(launch)와 검색(discovery)과 같은 필수 서비스와 신뢰 관계를 요구합니다.
우리는 학습 자원을 소비하는 커뮤니티나 조직이 해당 자원의 사용 방법(예: 맥락, 사용자 피드백, 사용자 순위, 평점, 주석 등)에 대한 정보를 수집하고, 이러한 파라데이터를 활동 레지스트리에 통합할 가능성을 상상합니다. 이러한 사용 데이터와 타사 분석 데이터는 자원 발견(resource discovery) 및 가장 효과적인 학습 자원을 이해하는 데 있어 귀중한 정보가 될 수 있을 것입니다.
학습 콘텐츠 메타데이터 : 학습 자원을 설명하는 데이터
활동 레지스트리를 효과적으로 구현하려면, 레지스트리가 가리키는 자원들이 어떤 방식으로든 설명되어야 합니다. 이러한 설명은 메타데이터로 인코딩됩니다. 교육 및 훈련 분야에서는 이미 여러 가지 메타데이터 형식이 탐구되어 왔으며, 여기에는 SCORM 관리 콘텐츠와 함께 자주 사용되는 학습 객체 메타데이터(LOM; IEEE 1484.1.1), 더블린 코어 메타데이터 이니셔티브(Dublin Core Metadata Initiative), 그리고 학습 자원 메타데이터 이니셔티브(LRMI)가 포함됩니다.
LRMI는 특히 웹 기반 교육에서 학습 자원을 설명하는 데 널리 사용되는 메타데이터 프레임워크입니다. LRMI는 2013년 4월, Schema.org에 채택되었으며, 이를 통해 교육 콘텐츠를 게시하거나 관리하는 누구나 자신들의 자원에 대한 풍부하고 교육에 특화된 메타데이터를 제공할 수 있습니다. 또한, 이러한 메타데이터가 주요 검색 엔진에서 인식될 것이라는 신뢰를 얻을 수 있습니다.
Schema.org는 Google, Microsoft, Yahoo, Yandex가 설립했으며, 인터넷 상의 구조화된 데이터(웹페이지, 이메일 메시지 등)를 위한 스키마를 생성, 유지, 홍보하는 것을 목표로 하는 개방형 커뮤니티 프로세스에 의해 개발됩니다. LRMI가 Schema.org에 통합됨으로써 많은 이점이 제공됩니다. 이론적으로, Schema.org의 거의 모든 “thing”이 학습 자원으로 정의될 수 있습니다.
따라서, LRMI는 학습 목적으로 의도적으로 사용되는 콘텐츠를 구별하는 메타데이터 속성을 다룹니다. 이를 위해 학습 자원 속성이 주요 루트 유형(root types)에 추가되었습니다. 예를 들어, LRMI는 CreativeWork 속성을 포함하며, 이 속성은 다음과 같은 설명자를 포함합니다:
• 교육적 용도(Educational Use)
• 교육적 정렬(Educational Alignment)
• 코스(Course): 이는 지식, 역량, 또는 학습자의 능력을 향상시키는 것을 목표로 하는 하나 이상의 교육 이벤트 및/또는 기타 유형의 CreativeWork로 구성된 시퀀스(sequence)로 정의됩니다.
인재 관리 : 교육, 훈련, 그리고 인력 관리 간의 단절된 시스템 연결하기
이전 섹션에서는 기술 표준이 제공하는 상호운용성을 강조했습니다. 우리는 주로 이러한 표준을 훈련과 교육 맥락에서 논의했지만, 이러한 표준은 인력 활동에도 적용됩니다. 인적 자원(HR), 훈련, 교육의 세계는 그 어느 때보다 서로 긴밀히 연결되어야 합니다. 조직, 직원, 부서, 데이터, 고객, 그리고 파트너는 이제 독립적인 사일로(silo) 안에서 성공적으로 작동할 수 없습니다.
그러나 오늘날의 훈련 및 교육 시스템은 여전히 종종 분리되어 있으며, 내부 또는 외부 HR 시스템과도 상호운용성이 부족합니다. 이는 불완전하거나 중복된 데이터, 비효율적이거나 부정확한 보고, 복잡하고 비용이 많이 드는 벤더 관리, 비효율적이고 수작업에 의존하는 HR 처리 등의 문제를 초래합니다. 이러한 분리된 시스템이 상호 소통할 수 있게 만드는 표준과 사양은 모든 규모의 조직이 성과와 직원 만족도를 개선하는 데 도움을 줄 수 있습니다.
미래 학습 생태계에서, 직원의 디지털 기록에는 채용, 훈련 및 개발, 성과 관리와 관련된 다양한 경력 단계에서의 데이터가 포함될 것입니다. 현재 국제 표준화 기구(ISO)를 통해 규정 준수 및 윤리, 인력 비용, 다양성, 리더십, 직업 건강 및 안전, 조직 문화, 생산성, 채용, 이동성과 이직률, 기술과 역량, 승계 계획, 인력 가용성과 같은 비즈니스에 중요한 영역에 대한 새로운 표준들이 적극적으로 개발되고 있습니다. 이러한 모든 영역에는 특정 지표와 보고 권장 사항이 포함됩니다.
훈련 및 교육 정보를 다른 인력 데이터와 결합할 수 있는 시스템을 구축하면 증거 기반 인적 자본 관리 정책의 발전을 가능하게 하고, 거래 처리를 위한 생애 주기 데이터를 제공합니다. 또한, 이는 인력 계획 및 전략적 의사결정에 필요한 데이터를 제공할 것입니다.
인재 관리가 너무 자주 후순위로 다뤄지고 있습니다. 은퇴가 증가하고 유동적인 노동력이 확대되면서, 조직은 여러 부처에서 사용하는 중복된 HR IT 시스템 때문에 종합적인 직원 데이터 생애 주기 관리를 점점 더 어렵게 느끼고 있습니다. 오늘날 사용되는 다양한 시스템은 서로 다른 언어, 관습, 종교를 가진 다른 국가들과도 같습니다. 이들은 다양한 데이터 형식을 사용하며, 데이터를 이동시키는 과정은 어렵고, 비표준 방식으로 이루어질 때가 많습니다.
HR 시스템의 상호운용성을 개선하려면, 각 직원의 고용부터 퇴직까지의 생애 주기를 포괄하는 공통 기록이 필요합니다. 또한, 조직 내 더 큰 시너지를 이루고 조직 역량 전반에서 인적 자본 성과를 향상시키기 위해, 조직은 임시적인 인재 관리 프로그램에서 벗어나 전략적인 인재 관리 프로그램으로 전환해야 합니다.
이러한 인력 HR 시스템의 개선은 학습 기관에도 이익을 가져다줄 것입니다. 전문가들은 대부분의 학습이 직장에서 이루어진다는 데 일반적으로 동의합니다. 실무 경험을 통해 개인은 직무 기술을 연마하고, 의사결정을 내리며, 문제를 해결하고, 조직 내 다른 사람들과 상호작용합니다. 또한, 실수를 통해 배우고, 성과에 대한 피드백을 받으며, 코칭, 멘토링, 협력 학습, 기타 사회적 학습에 참여합니다. 그러나 이러한 비공식 학습 경험은 거의 추적되지 않습니다. 이러한 학습이 언제, 어떻게 발생하는지 이해함으로써, 우리는 개인의 학습 여정을 정보화하거나 조직의 집단적 지능을 높이는 데 있어 더욱 강력한 개인 프로파일을 구축할 수 있습니다.
조직이 혁신, 변화, 효과를 높일 수 있는 역량은 직원들의 능력에 달려 있습니다. 이는 개인 개발의 중요성을 강조합니다. 그러나 학부 성과를 측정하기 위한 더 나은 지표가 필요한 것처럼, 직장에서의 성과를 측정하기 위한 더 나은 지표도 필요합니다. 글로벌 경제와 세계 무대의 경쟁이 심화되면서, 조직이 활용하는 인적 자본 공급망에 초점을 맞출 필요성이 커지고 있습니다.
이 개념은 조직에 매력적이지만, 구현 과정에서 지속적인 도전 과제가 있습니다. 인력 계획에는 적절한 모델링과 예측 분석을 위한 권위 있는 데이터가 필요합니다. 채용 전략을 개선하기 위해서는 온보딩 및 성과 데이터와의 통합이 필요합니다. 서로 다른 시스템이 읽고 쓰는 공통 언어를 가능하게 하면, 조직 내 숨겨진 의존성과 관계를 식별하고, 더 나은 데이터 기반 의사결정을 지원하는 분석 정보를 제공할 수 있습니다.
이 이니셔티브의 일환으로, 직업 데이터 교환(Job Data Exchange)을 개발하고 있습니다. 이는 고용주와 HR 기술 파트너가 사용할 수 있는 일련의 오픈 데이터 자원, 알고리즘, 참조 애플리케이션을 제공하여, 역량 기반 채용 요건을 정의하고 검증하며 전달하는 방식을 개선합니다. 이를 통해 직무 성과 데이터, 자격 인증 시스템, 학습 기록 시스템 간의 중요한 연결고리를 제공합니다.
실행 전략
미래 학습 생태계는 서로 연결된 정보 시스템과 기기들로 구성된 점점 더 복잡한 세상을 제공합니다. 이러한 새로운 애플리케이션이 가진 약속은 대규모로 정보를 생성, 수집, 전송, 처리, 보관할 수 있는 능력에서 비롯됩니다. 그러나 수집되고 저장되는 개인 정보의 양의 급격한 증가와 이를 다른 정보와 결합하여 분석할 수 있는 능력의 향상은, 이러한 대량의 데이터를 책임감 있게 관리해야 한다는 정당한 우려를 낳습니다.
학습 데이터를 의미 있게 만드는 데 필요한 기본 시스템, 구성 요소 제품, 그리고 서비스들을 강화하는 것은 시급한 과제입니다. 아래 섹션에서는 조직의 필요에 따라 적응하고 성장할 수 있는 엔터프라이즈 전체 학습 생태계를 구축하기 위한 기초를 설명합니다.
1. 조직의 역량을 식별하고 설명하라
조직은 기관 내 모든 비즈니스 기능을 성공적으로 수행하는 데 필요한 기술을 목록화해야 합니다. 여기에는 여러 부서, 사업부, 또는 비즈니스 라인에 걸쳐 필요한 기술적, 전문적, 리더십 역량이 포함됩니다.
조직 내 각 역할은 일반적으로 경력 경로와 이에 수반되는 학습 경로를 포함합니다. 이는 직원이 업무를 효과적으로 수행하는 데 필요한 지식, 기술, 태도, 기타 기여 요인을 의미합니다.
다른 역할이 동일한 역량을 공유할 수 있지만, 그 역량이 수행되는 맥락이나 해당 업무에 미치는 영향의 가중치는 다를 수 있습니다. 역량 프레임워크는 HR, 훈련, 교육 시스템 간의 공통 참조 모델을 제공합니다. 또한 프레임워크 내에서 역량과 관련된 핵심 지표는 개인의 성과를 정량화하는 데 도움을 줍니다.
새로운 도구, 기술, 프로세스가 작업 환경에 도입됨에 따라, 역량 모델도 미래에 효과적으로 운영될 수 있도록 지속적으로 업데이트되어야 합니다.
2. 데이터 전략을 수립하라
현재의 분산된 학습 및 인사 시스템 환경은 앞으로도 계속 진화할 것입니다. 통합된 데이터 전략은 다음과 같은 사항을 지원하기 위해 필요합니다:
• 인적 자본 공급망을 지원하는 데 필요한 모든 관련 데이터 유형을 식별
• 시간 경과에 따른 데이터 유형의 관련성 정의
• 서로 다른 데이터 유형 간의 중요성 감소(데이터 유효성 저하)를 캡처하기 위한 접근 방식 식별
• 각 데이터 유형을 생성하는 권위 있는 출처를 정의
효과적인 데이터 레이블링 전략은 자동화, 분석의 향상, 그리고 데이터 요소의 수명주기 관리를 가능하게 합니다. 데이터 레이블링은 평생 학습의 연속성에 걸쳐 데이터를 생성하는 다양한 시스템과 연관된 데이터 유형에 의미를 부여합니다. 이를 통해 학습 생태계 내 모든 시스템이 필요에 따라 데이터를 사용할 수 있게 하며, 예를 들어 개인별 맞춤 학습을 적응적으로 조정할 수 있습니다.
또한, 패턴 데이터 분석을 통해 조직 차원에서 추가적인 통찰력을 도출할 수 있는 가능성을 모색해야 합니다. 다양한 영역에서 생성되는 구조적 데이터와 비구조적 데이터 모두를 고려하고, 필요한 데이터를 모든 구성 요소가 접근할 수 있도록 데이터 유형을 클러스터링하는 전략을 개발해야 합니다.
3. 표준, 사양, 어휘를 정의하라
국가 전반에서 사용되는 표준, 사양, 공유 어휘의 요구사항을 공식화할수록 생태계에 구성 요소를 통합하기가 더 쉬워집니다.
다양한 용어를 의미적으로 정렬할 수 있는 자동화된 기술이 많이 존재하지만, 학습 활동, 디지털 콘텐츠, 학습자, 역량을 설명하는 데 공유 어휘를 사용하는 시스템을 설계하는 것은 많은 이점을 제공합니다.
학습 활동 전반에서 활동 추적(activity tracking)이 효과적으로 작동하려면, 각 활동이 다양한 교육 방식, 미디어 유형 또는 조직의 다른 시스템(예: 인재 관리)에 통합될 수 있는 공통 용어 라이브러리를 사용해야 합니다.
4. 거버넌스 전략을 정의하라
조직은 미래를 대비하여 현재의 인력을 채용하고 교육하며 준비하는 데 능동적이고 선제적으로 대응해야 합니다. 오늘날 성공에 필요한 지식과 기술은 변화할 것이며, 새로운 도구, 기술, 방법론이 조직에 도입될 것입니다.
개인 식별 정보, 보호된 지적 재산, 그리고 기타 조직의 독점 데이터를 보호하는 데 중점을 두어야 합니다. 새로운 시스템이 도입되면, 데이터 전략, 역량 프레임워크, 인적 자본 공급망의 모든 측면이 개정되어야 합니다. 인력 계획 전략은 이러한 중요한 구성 요소의 수명주기 관리와 연결되어야 합니다.
제가 생각하기에 첫 번째 질문은 각 군종 간에 공통적으로 적용 가능한 소화 가능한 부분이 무엇인지 알아내는 것입니다. 이것을 결정할 수 있다면, 그 공통된 부분에 대해 동의를 얻는 방법은 무엇인가라는 질문으로 이어질 것입니다.
결국, 우리 모두는 어떻게 더 나은 방식으로, 더 빠르고, 더 저렴하게 실행할 수 있을지 알고 싶어 합니다. 이는 모든 군종이 직면한 공통적인 문제입니다.
Thomas Baptiste
Lieutenant General, U.S. Air Force (Ret.)
President and CEO, the National Center for Simulation
데이터 전략에서도 거버넌스를 다뤄야 하며, 이를 통해 특정 지표와 결과를 추적, 측정, 분석할 수 있어야 합니다.
이 네 가지 단계는 학습 생태계를 구축하기 위한 전략적 틀을 제공합니다. 이러한 작업은 간단하지 않으며, 조직의 규모, 복잡성, 목표에 따라 각기 다르게 구현될 것입니다.
그러나 이러한 단계들을 종합적으로 적용하면 조직은 미래 학습 생태계 개념을 수용할 수 있으며, 이를 통해 생성되는 풍부한 데이터로부터 이점을 얻을 수 있습니다. 이를 통해 기업은 인적 자본을 최대한 활용할 수 있고, 학습 제공 기관은 제공하는 교육 및 훈련 경험의 품질을 최적화하고 관리할 수 있게 됩니다.
예를 들어, 지식의 발전, 학생들의 성공 보장, 그리고 더 많은 사람들에게 영향을 미칠 수 있는 실천 방법의 개발 촉진에도 큰 가치가 있습니다.
이러한 다차원적 접근은 새로운 것이 아닙니다. 인간 대상 연구 심사에서 이미 많은 가치들이 고려되고 있습니다. 따라서 학문적 커뮤니티가 연구뿐만 아니라 실천적 평가에서도 이처럼 다양한 가치를 종합적으로 고려하는 유사한 프로세스를 구축하는 것이 중요합니다.
Martin Kurzweil, J.D.
Director, Educational Transformation Program, Ithaka S+R