데이터 유출은 교통사고처럼 불가피한 측면이 있습니다. 그러나 디지털 학습자 생태계로의 전환은 국가적으로 반드시 이루어져야 할 과제입니다. 따라서, 본 장에서는 학습자 데이터 시스템에서 데이터 유출의 발생 가능성, 피해 규모, 그리고 전염 가능성을 동시에 관리할 수 있는 적극적인 접근법을 설명합니다.
효과적인 학습 아키텍처를 구축하려면 프라이버시 보호, 개인의 부정행위 방지, 외부 위협 요소의 침입 방지를 위한 보안 체계가 필요합니다. 이를 위해 기밀성(confidentiality), 무결성(integrity), 접근성(accessibility)이라는 보안의 세 가지 축에 균형 잡힌 노력이 요구됩니다.
대부분의 보안 연구는 기밀성과 무결성에 초점을 맞추지만, 데이터를 접근할 수 있는 능력은 적시적이고 정보에 기반한 의사 결정을 가능하게 합니다. 또한, 사용자가 접근성을 충분히 확보하지 못할 경우, 보안 통제를 무효화할 가능성이 매우 높습니다.
이러한 문제를 해결하기 위해서는 사용자를 중심으로 한 기기 및 네트워크 보안 강화가 이루어져야 합니다. 이를 효율적으로 구현하려면, 데이터 보안 설계가 현재 및 미래의 학습 아키텍처 내에서 유출의 확산을 제한할 수 있도록 지원해야 합니다.
따라서 본 장에서는 사이버 보안 발전에 발맞춘 분산 학습 환경을 유지하기 위한 원칙과 전략을 제시합니다.
데이터 보안 위협과 과제
데이터 축적을 수용하는 국가로 나아가는 과정에서 해결해야 할 여러 가지 문제가 존재합니다. 우리는 개인을 보호하는 요소뿐만 아니라, 시스템과 데이터 무결성을 보호할 필요성도 인식해야 합니다.
미국에서는 개인의 프라이버시가 기본권으로 간주되며, 보안은 이러한 프라이버시가 가져다주는 존엄성을 지키는 수단입니다. 그러나 일부 학습자들은 무결성을 위협하는 행동을 합니다. 예를 들어, 접근 통제를 우회하여 답안을 훔치거나 성적을 조작하는 경우가 있습니다.
또한, 외국의 적대 세력은 사이버 수단을 이용해 국가 역량을 평가하거나 조직의 우선순위에 영향을 미치려는 시도를 지속적으로 하고 있습니다.
마지막으로, 자원 투자가 이루어지고 있음에도 불구하고 유출 사고의 영향과 발생 확률이 지속적으로 증가하고 있는 현실도 주목해야 합니다.
아마추어 위협
가장 시급한 문제는 악성 소프트웨어가 점점 더 자동화되고 있다는 점입니다. 학습자들이 답안을 훔치거나 성적을 변경하는 데 필요한 기술적 능력은 거의 요구되지 않습니다. 수천 개에 이르는 무료 단계별 튜토리얼이 존재하며, 이를 통해 잠재적인 공격자들에게 가장 널리 알려진 기술적 침투 과정을 하나씩 안내하고 있습니다.
외국 위협
외국의 적대 세력과 관련하여 더 큰 도전 과제가 존재합니다. 고급 지속 위협(Advanced Persistent Threats)이 점점 더 정교해짐에 따라 기존의 보안 기둥들은 빠르게 구식이 되고 있습니다. 이는 특히 양자 및 고전 슈퍼컴퓨팅 능력에서 적대 세력의 발전 속도를 따라잡기 위해 우리 국가가 경쟁하고 있는 상황에서 더욱 두드러집니다.
데이터 관리 시스템이 광범위하게 사용될 경우, 이미 알려진 공격 방법에 대해 탄력적으로 대응할 수 있어야 하며, 암호 해독을 위한 무차별 대입 공격(brute force), 사이드 채널 공격(side channel attacks), 인터셉트 공격(intercept attacks)에 대해서도 검증된 보안을 제공해야 합니다.
사회공학(Social Engineering)
조직의 학습 아키텍처에 대한 접근 권한의 가치는 과소평가되어서는 안 됩니다. 전문적인 수준의 사회공학은 전체 사회의 행동을 조작하는 결과를 가져올 수 있습니다. 이는 기만과 선전을 활용해 대중을 통제하는 광범위하고 깊은 지식 체계를 기반으로 합니다. 이러한 사회공학은 개인 수준에서 신뢰를 이용한 사기를 통해 이루어지며, 유사한 기법을 사용해 대규모 인원을 대상으로 확장할 수도 있습니다.
러시아의 군사 이론과 정부 차원의 사회공학 실험에서 수 세기에 걸쳐 발전된 “마스키로브카(маскировка)” 개념은 이러한 영역을 잘 보여줍니다. 이 단어는 대략 “가장”, “위장”, 또는 “기만”으로 번역될 수 있으며, 반사적 통제(reflective control)라는 개념을 포함합니다. 반사적 통제란, 전략적으로 (대개 진실인) 정보를 투입해 특정 개인이나 사회가 자유롭게 행동을 선택하도록 유도하지만, 그 행동이 다른 당사자에게 가장 이익이 되는 방식을 가리킵니다.
진실을 선택적으로 투입하는 것만으로도 인식을 조작할 수 있습니다. 더 나아가, 신뢰받는 환경 내에서 잘 설계된 거짓 정보 하나는 불균형적인 네트워크 효과를 초래할 수 있습니다. 개인이 다른 사람의 이익을 위해 행동하도록 조작될 수 있는 것처럼, 조직도 동일하게 조작될 수 있습니다. 사회적 차원에서는 이러한 조작이 정치적 의지를 형성하고 궁극적으로 공공 정책에까지 영향을 미칩니다.
투자 모델
최근 정보 보안 경제학 연구에서는 정보 보안 투자의 최적 수준을 평가하는 데 도움을 주는 모델을 구축하려는 시도가 이루어졌습니다. 이러한 모델은 일반적으로 위험 관리 전략을 적용해 예상 금전적 손실, 평가된 취약점, 그리고 침해 가능성과 관련된 최적화 함수를 계산합니다. 일부 모델은 침해 전염 효과를 고려하기도 하지만, 경제적으로 최적화된 투자 금액을 어디에 투입해야 할지 구체적으로 제안하지는 않습니다.
경제학자들과 사이버 보안 전문가들 사이에서는 데이터를 보호할 수 있는 어떤 솔루션이든 더 많은 자금을 투입해야 한다는 합의가 있는 듯합니다. 그러나 이러한 보안 접근 방식은 모든 자동>차를 탱크로 만들기 위해 막대한 자원을 투입하는 것에 비유될 수 있습니다!
현재 모범 사례 요약
이후 사이버 공간은 공격자가 불균형한 비용 우위를 점하고 소모전을 통해 승리를 추구하는 비대칭 전장이 되었습니다. 이러한 문제들은 해결하기 어렵게 보일 수 있지만, 과도한 비용 없이도 분산 학습 아키텍처의 기밀성, 무결성, 접근성을 유지할 수 있는 특정 모범 사례가 존재합니다. 보안을 위한 가장 중요한 실천 사항은 표준, 요구사항, 프로토콜, 구현 방식을 정기적으로 검토하는 것입니다.
효과적인 사이버 보안은 기술의 세부 사항에 대한 철저한 검토를 요구하며, 이는 이 문서의 범위를 넘어서는 내용입니다. 따라서 포괄적인 검토 대신, 현재 분산 학습 프로토콜 내에서 존재하는 몇 가지 현재의 취약점을 고려합니다. 그 목표는 두 가지입니다.
첫째, 즉각적인 개선을 지원하고,
둘째, 지속적인 보안 유지를 통해 분산 학습 아키텍처의 비용 효율적인 신뢰성을 확보하는 것입니다.
이 장의 결론에서 제시되는 실행 계획은 구조화된 위험 관리 프로세스를 통해 실질적인 검토와 검증을 권장합니다. 이를 통해 우선순위가 매겨진 작업 목록을 생성하여 보안 강화에 기여할 수 있습니다.
미래 학습 생태계 구현 계층
데이터 보안은 일반 IT 분야에 비해 성숙한 동시에 지속적으로 발전하는 영역입니다. 이러한 모범 사례들은 일반적으로 운영 체제, 서버, 네트워크 기술을 기반으로 구축되는 분산 학습 아키텍처에도 적용됩니다. 그러나 미래 학습 생태계는 독자적인 상호운용성을 위한 데이터 형식, 전송 계층, 인터페이스, 저장 솔루션을 추가적으로 필요로 합니다.
그 예로는 xAPI와 Kafka가 있습니다.
경험 응용 프로그래밍 인터페이스 (xAPI)
xAPI는 온라인 및 오프라인 학습 경험 전반에 걸쳐 데이터를 수집할 수 있도록 하는 상호운용성 명세의 예입니다. 이는 다양한 학습 기술에서 수집된 데이터를 위한 표준화된 데이터 구조와 용어를 제공합니다. xAPI는 단순성과 유연성을 목표로 설계되었으며, 미래 학습 생태계 전반에서 학습을 소통하고 평가하는 기반을 제공합니다.
활용 가능한 분야로는 다음과 같은 사례들이 있습니다:
• 현실 세계 활동
• 경험 기반 학습
• 사회적 학습
• 시뮬레이션
• 모바일 학습
• 가상 세계
• 시리어스 게임(Serious Games)
xAPI 명세를 준수하는 시스템은 사람과 학습 콘텐츠 간의 상호작용 데이터를 기록합니다. 이러한 상호작용은 어디에서든 발생할 수 있으며, 종종 학습의 가능성을 나타냅니다. 기록 과정에서는 학습 기록 저장소(Learning Record Store, LRS)로 진술(statement)을 전송하는 방식으로 이루어집니다. xAPI 기술 명세의 일부인 LRS는 기록된 xAPI 진술을 다른 LRS 및 다양한 학습 기술과 공유할 수 있습니다(접근 통제 허용 범위 내에서).
xAPI 명세는 여러 구현 계층을 통해 이러한 상호운용성을 제공합니다.
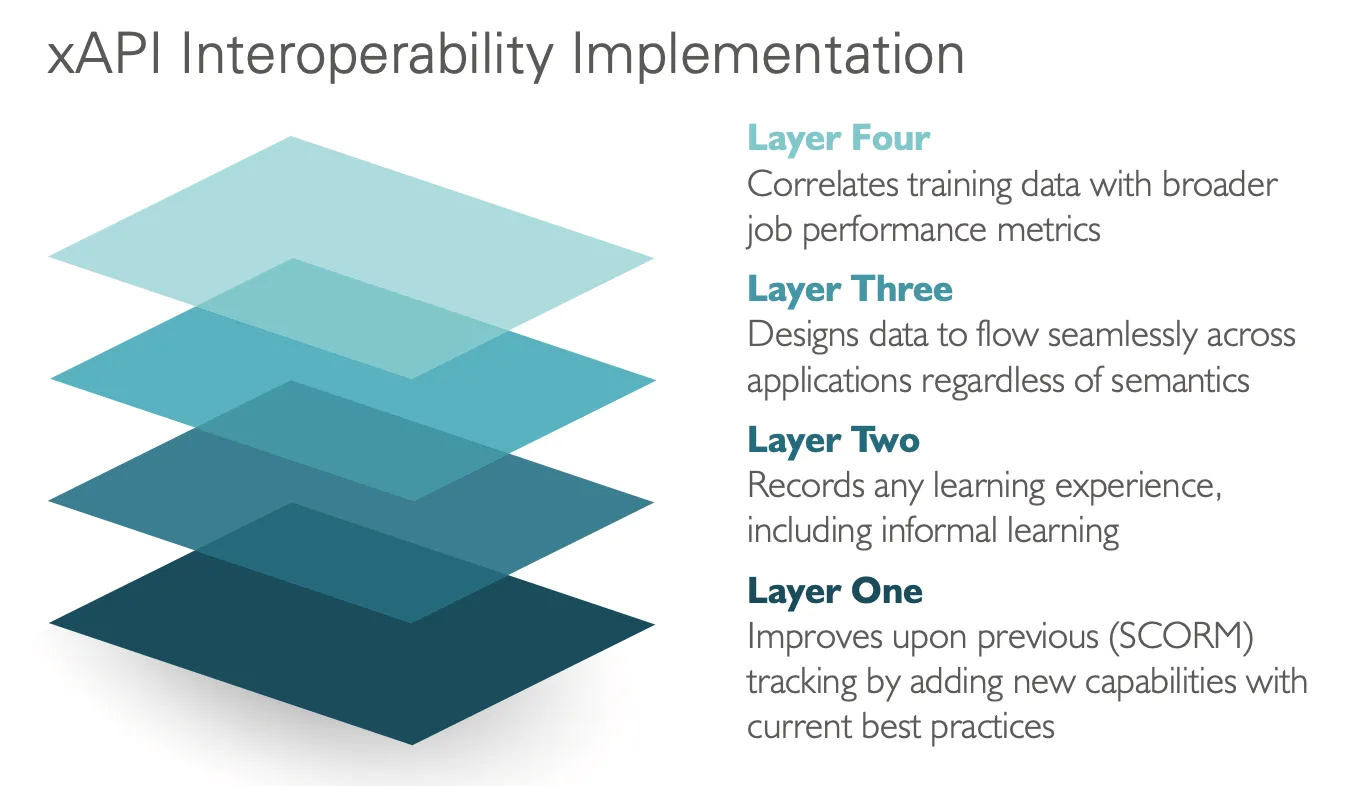
각 계층 내 및 계층 간의 보안은 조직이 불필요한 정보 위험에 노출되지 않으면서도 일관되고 신뢰할 수 있는 애플리케이션 실행을 가능하게 해야 합니다. 이는 xAPI가 추적하는 다양한 학습 상호작용 전반에서 데이터가 점점 더 표준화됨에 따라 특히 중요합니다.
모든 보안 평가의 첫 단계는 현재 적용 중인 통제 수단을 평가하는 것입니다. 예비 분석 결과, 즉각적인 검토가 필요한 여러 취약점이 존재한다는 사실이 드러났습니다.
Kafka
Apache Kafka는 대규모 학습 기록 변화를 처리할 수 있는 메시지 지향 미들웨어 시스템의 한 예입니다. 이 시스템은 LinkedIn에서 메시지 수집 및 분석 메커니즘으로 개발되었으며, 특히 실시간으로 대량의 가변적인 메시지 비율을 처리할 수 있는 기능으로 잘 알려져 있습니다.
Kafka의 주요 기능은 다음과 같습니다:
• 파티셔닝: 데이터를 분할하여 효율적으로 처리
• 복제: 데이터의 가용성과 안정성을 보장
• 장애 내성: 시스템 장애 발생 시에도 안정적으로 동작
이러한 기능 덕분에 Kafka는 빅데이터의 분산 메시징에 이상적이며, 신뢰할 수 있고 비동기적인 메시지 교환을 가능하게 하는 통합 플랫폼으로 간주됩니다.
접근성이 핵심입니다.
현재 우리 준비 태세에서 가장 큰 문제는 어떻게 훈련을 필요한 순간에 제공할 수 있는가입니다. 접근성은 우리가 집중해야 할 주요 과제입니다. 우리의 네트워크는 매우 안전하지만, 속도가 느리고 성능이 미흡합니다. 또한, BYOD(Bring Your Own Device, 개인 기기 사용) 정책이 있지만, 모든 해병이 태블릿이나 컴퓨터를 가지고 있는 것은 아니며, 대부분 휴대폰만 보유하고 있습니다.
따라서 진정한 질문은 “접근성과 보안 사이에서 어떻게 균형을 잡을 것인가?”입니다. 저는 항상 네트워크 팀과 논쟁하는 것 같은 기분입니다—“미션의 목표가 보안인가, 학습인가?” 두 가지 모두를 충족할 수 있는 방법은 무엇일까요?
Larry Smith
Technical Director
U.S. Marine Corps College of Distance Education and Training
학습 처리에 사용할 수 있는 메시지 기반 미들웨어의 다른 예로는 국제 표준(ISO/IEC 19464)인 Advanced Message Queuing Protocol 1.0을 기반으로 한 시스템이 있습니다. 이 프로토콜은 소규모 시스템에 최적화된 여러 구현 옵션을 제공합니다. 이러한 옵션에는 ActiveMQ, Apache Qpid, RabbitMQ 등이 포함됩니다.
미래 학습 생태계에서 데이터 보안을 위한 비전
표준과 모범 사례가 변화함에 따라 분산 학습 아키텍처 내 구현도 변화해야 합니다. 이는 학습자 데이터 보안에 대해 실질적이고 지속적인 평가를 가능하게 하는 이론적 관점이 필요하다는 것을 의미합니다.
인간이 만든 어떤 것도 완벽히 방어할 수 없으며, 데이터 공유 역시 피할 수 없습니다. 분산 학습의 영역에서는 학생이 데이터 스트림을 해킹하여 시험 답안을 얻거나 정교한 공격이 정보를 탈취하거나 변경하는 위험을 완전히 제거할 수 없다는 점을 인정해야 합니다. 그러나 우리는 다음과 같은 방법을 찾아야 합니다:
• (a) 성공적인 공격의 가능성을 줄이는 방법, 그리고
• (b) 침해가 발생할 경우 그 영향을 최소화하는 장벽을 개발하는 방법.
정상 사고 이론(Normal Accident Theory)의 핵심 원칙은 시스템이 복잡하고 긴밀히 연결되어 있으며, 치명적인 잠재력을 지니고 있을 경우 기술적 실패는 필연적이라는 점입니다.
따라서, 다음과 같은 상호의존적 복합 시스템에서 발생할 수 있는 문제를 고려해야 합니다:
• 신원 확인
• 접근 통제
• 권한 부여
• 감사
• 네트워크 분할 및 경계 강화
• 엔드포인트 보호
• 암호화
• 트랜잭션 보안
정상 사고 이론의 가정은 다음과 같습니다:
-
인간은 오류를 발생시킨다.
-
작은 사고는 종종 큰 사고로 확산된다.
-
문제를 야기하는 것은 기술 그 자체가 아니라 기술의 조직화 방식이다.
현재의 정상 사고 이론과 조직 신뢰성 연구에 따르면, 침해를 피할 수 없음을 전제로 하고 침해의 확산을 방지하는 전략을 설계해야 한다는 점이 시사됩니다.
모든 분산 학습 아키텍처 내 시스템은 이미 손상되었거나 결국 손상될 가능성이 있습니다. 따라서 우리의 목표는 그 영향을 최소화하는 것입니다. 실질적인 관점에서, 분산 학습에 대한 권장 사항은 다음과 같습니다:
• 네트워크 및 조직 분리를 통한 데이터 레이크(Data Lakes)의 분리 유지:
각 부서 또는 기관은 별도의 콘텐츠 네트워크를 유지하며, 네트워크 내에서 각 학습자 유형에 맞춘 분리된 구역을 구축해야 합니다. 이를 통해 침해 확산을 억제하고 데이터 무결성을 유지할 수 있습니다.
• 콘텐츠 블록체인을 통해 데이터 무결성 보존:
중앙에서 관리되는 콘텐츠의 동기화 및 구독을 통해 기밀성을 유지하며, 조직의 우선순위와 전략적 목표를 드러낼 수 있는 데이터 집계를 방지해야 합니다.
이 섹션의 나머지 부분에서는 네트워크 및 엔드포인트 보호를 단기적으로 보장하고, 장기적으로 보안의 지속 가능성을 확보하기 위한 구체적인 보안 문제를 다룹니다.
네트워크 강화
정보 저장 및 검색 시스템의 고도의 기술적 특성은 침입 탐지 시스템(IDS)과 침입 방지 시스템(IPS)이 침해 식별에 유용한 구성 요소가 되게 합니다. 대부분의 IDS와 IPS는 네트워크 트래픽을 모니터링하지만, 호스트 기반 이상 탐지(host-based anomaly detection)는 시험 답안에 대한 무단 접근 시도나 성적 조작을 식별하고 보고할 수 있습니다.
또한, 보안 사고 및 이벤트 관리 도구(Security Incident and Event Management, SIEM)가 상용화되어 있으며, 이는 네트워크 로그와 데이터 흐름을 모니터링하여 침해 지표를 탐지합니다. 이러한 도구를 활용하면 보안 침해에 대한 인식을 크게 높이고, 탐지 시간을 단축하며, 조직이 필요한 대응 조치를 계획하는 데 도움을 줄 수 있습니다.
분산 학습 환경에서는 데이터 스트림을 일방향 밸브(one-way valves)로 설계하는 것이 권장됩니다. 데이터 레이크는 SIEM과 조직의 보안 운영 센터(Security Operations Centers, SOC)를 통해 철저히 감시되어야 합니다. SOC는 SIEM 데이터를 모니터링하고 24시간 실시간 대응을 수행합니다.
자체 방어를 유지하기에 조직 규모가 너무 작은 경우, 관리형 보안 서비스 제공업체(Managed Security Services Providers, MSSPs)를 통해 SOC 기능을 이용할 수 있습니다. 이를 통해 소규모 조직도 효과적인 방어 체계를 구축할 수 있습니다.
최첨단 보안 기술의 적용 및 통합
xAPI와 Kafka 표준을 Kerberos 프로토콜의 관점에서 보다 심층적으로 검토하면 현재의 보안 체계에 대한 우아한 대안을 도출할 수 있을 것입니다. 또한, API 내에 강력한 보안 계층을 통합하면 콘텐츠 제공자와 분산 학습 호스트 전반에서 인증 메커니즘을 간소화하는 추상화를 제공할 수 있습니다.
Kerberos는 매사추세츠공과대학교(MIT)에서 캠퍼스 내 통신을 위한 네트워크 인증 프로토콜로 개발되었습니다. 이 프로토콜의 주요 강점은 안전하지 않은 네트워크 환경에서도 보안을 유지하도록 설계되었다는 점입니다. 구체적으로, 인증 세션 동안 비밀번호가 네트워크를 통해 전송되지 않습니다. 각 전송은 비밀 키를 사용하여 암호화되며, 공격자는 암호화 키를 손상시키거나 암호화 알고리즘을 해독하지 않는 한 서비스에 무단으로 접근할 수 없습니다.
Kerberos는 재전송 공격(replay attack)에도 대응할 수 있습니다. 재전송 공격은 공격자가 합법적인 통신 내용을 엿듣고 이를 다시 전송하는 방식입니다. 이 프로토콜은 대칭 키 암호화를 사용하므로, 장치 수준에서 계산 효율성을 제공하며 자원이 제한된 장치에서도 사용하기 적합합니다. 대칭 키 암호화는 공개 키 인프라(Public Key Infrastructure) 내 인증 기관(Certificate Authority)이 손상될 가능성에 대한 복원력을 제공합니다.
마지막으로, Kerberos는 오픈소스 구현이 널리 보급되어 있어, 정부 소유 시스템에 비독점적으로 통합하기 용이합니다. 이를 통해 비용 효율적이고 강력한 보안 솔루션을 구축할 수 있습니다.
디바이스 보안 강화
디바이스 보안을 강화하는 가장 효과적인 방법은 공격자의 관점에서 시스템을 손상시키려는 시도를 예측하는 것입니다. 공격과 방어 시뮬레이션을 통해 방어자는 가장 중요한 취약점이 어떤 방식으로 악용되는지 학습하고, 보안 결함을 해결할 방법을 모색할 수 있습니다.
정기적인 침투 테스트는 각 디바이스 및 네트워크 전반의 취약점을 드러내는 데 도움을 줍니다. 특히 분산 학습 아키텍처에서 이는 다음과 같은 중요한 디바이스에 대해 필수적입니다:
• 개인화 학습 데이터 저장소 네트워크의 접근 제어와 관련된 디바이스 (예: 공개 키 저장소, 도메인 컨트롤러, 인증 기관, 인증 서버)
• 평가 자료를 포함하는 콘텐츠 저장소 (예: 정답 키를 포함한 리포지토리)
이러한 디바이스에 대한 취약점 분석은 분산 학습 환경의 보안 수준을 강화하는 데 핵심적인 역할을 합니다.
사회적 보안 강화: 회복력 개발
사회적 보안 강화에서 학습 관리는 핵심 요소로 작용합니다. 네트워크와 디바이스 보안을 강화하는 비용을 절감하기 위해, 조직 내에서 인간 행동을 명확히 평가하고, 이에 따른 교육 개입을 설계해야 합니다. 보안 관점에서 사회적 보안 강화는 조직의 회복력(resiliency)을 개발할 기회를 제공합니다.
이는 구성원이 기술적 통제 장치의 설계 배경에 담긴 “이유”를 이해하고, 이를 통해 데이터 유출을 방지하고 문제를 억제할 수 있는 방법을 학습하는 데서 시작됩니다. 그러나 사회적 보안 강화의 가장 중요한 구성 요소는 최고의 관행(best practices)을 유지하고 조직 내에 정착시키는 문화, 즉 제도적 유지(institutional retention)를 구축하는 것입니다.
이를 통해 조직은 보안 사고에 더 잘 대처할 수 있는 환경을 만들어 나갈 수 있습니다.
예시 – 사회적 보안 강화 활동
퍼플 팀(Purple team) 연습은 사회적 보안 강화를 위한 하나의 효과적인 방법입니다. 이러한 연습은 네트워크 수비수들이 자신의 네트워크에서 공격이 어떻게 이루어지는지 학습할 수 있도록 합니다. 테스트와 훈련 활동은 IT 직원과 조직 내 관리 계층을 포함한 다양한 참여자들이 참여하는 실시간 공격/방어 시나리오로 구성됩니다.
레드 팀(Red team)으로 불리는 침투 테스트 팀은 공개적으로 공격을 시도하며, 블루 팀(Blue team)으로 불리는 위협 사냥 수비팀은 이를 실시간으로 탐지하고 방어합니다. 이러한 시나리오는 조직의 실제 환경, 해당 환경의 가상 복제본, 또는 비슷한 환경에서 재현된 재난 시뮬레이션으로 진행될 수 있습니다.
퍼플 팀 시나리오에는 초보자와 전문가 수준의 최종 사용자 그룹을 포함시키는 것도 가능합니다. 이들은 자신의 경험을 바탕으로 보안 통제를 우회하려는 이유, 시점, 방법에 대한 귀중한 통찰을 제공합니다. 이러한 참여는 공격 탐지 시간을 단축하고, 조직의 대응 절차를 테스트하며, 이전에 숨겨져 있던 취약점을 발견하고, 궁극적으로 보다 강화된 조직 보안 태세로 이어집니다.
퍼플 팀 연습은 일반적으로 내부 직원에 의해 수행되며, 독립적인 제3자가 이를 주관할 때 가장 효과적입니다. 내부 레드 팀이 부재할 경우, 외부 침투 테스트가 강력한 대안이 될 수 있습니다.
실행 권장 사항
미래 학습 생태계의 보안을 구현하기 위한 계획은 4단계로 나뉠 수 있습니다. 이러한 계획은 확장 가능하고 미래 지향적인 방식으로 사이버 보안 역량을 가장 신속하고 비용 효율적으로 향상시키는 방법이 될 것입니다.
1단계: 보안 요구 사항 정의
보안의 필요성은 자명하지만, 어떤 표준을 강제할 것인지는 명확하지 않습니다. 보안 요구 사항 엔지니어링은 이 과정의 첫 번째 단계로, 시스템 간 상호 운용성 요구 사항을 체계적으로 검토합니다. 이 단계에서는 다음과 같은 작업이 이루어집니다:
• 이미 실행 중인 다양한 보안 절차를 확인하고 스트레스 테스트를 수행합니다.
• 해당 보호 조치 중 어느 부분이 불충분한지를 검증합니다.
• 현재 콘텐츠 제공자와 협력하여 공격/방어 연습을 실시해 발견 사항을 검증합니다.
이 과정은 가장 가능성이 높고, 중요하며, 영향력이 큰 보안 개선 사항에 자원을 우선적으로 배치하도록 지원하여 가용 자원의 경제적 활용으로 이어질 것입니다.
예시 – 실행 활동
1단계에서는 여러 퍼플 팀 연습(Purple Team Exercises)이 포함될 가능성이 높습니다. 이 연습은 침투 테스트 팀(레드 팀)이 공격을 수행하고, 위협을 탐지하는 방어 팀(블루 팀)이 실시간으로 해당 공격을 발견하고 차단하는 방식으로 진행됩니다. 이러한 시나리오는 일반적으로 조직의 실제 환경이나 그 환경을 가상으로 복제한 환경에서 이루어지기 때문에 지역적이고 맥락화된 학습을 제공합니다.
2단계에서는 1단계에서 수행된 퍼플 팀 연습을 통해 얻은 지역 학습 경험을 다양한 형식의 교육 콘텐츠로 전환하는 작업이 이루어져야 합니다. 이를 위해 1단계에서 작성된 노트와 발견 사항을 기반으로 사례 연구를 작성하고, 이를 통해 더 넓은 커뮤니티를 교육할 수 있도록 준비해야 합니다. 예를 들어, 다음과 같은 형태가 포함될 수 있습니다:
• 강의 자료: 사이버 보안 위협 및 프로토콜에 대한 이론 교육
• 온라인 실험실: 실습 중심의 학습 환경 제공
• 평가 자료: 학습 기술자들이 자신들의 조직 내에서의 위협 및 보안 프로토콜을 배우고 이해할 수 있도록 설계된 평가 자료이러한 활동은 학습 기술자와 관련 이해관계자들이 자신들의 환경에서의 보안 위협과 대응 방법을 더욱 잘 이해할 수 있도록 돕습니다.
2단계: 보안 학습 활동 설계, 구현 및 평가
새로운 프로세스를 학습하는 것은 미래에 지속적인 개선을 예측하고 실현할 수 있는 최적의 방법 중 하나입니다. 1단계가 실행되는 동안, 보안 요구 사항 엔지니어링의 실천을 모니터링하고 평가할 기회가 있습니다. 이러한 평가 결과는 실제 분산 학습 아키텍처에서 파생된 사용 사례를 바탕으로 개별적 및 조직적 학습 활동을 생성할 수 있습니다. 또한, 1단계와 2단계의 일정 및 팀을 통합하면 비용 효율성을 극대화할 가능성이 높습니다.
이 학습 활동은 분산 학습 환경에서 보안 엔지니어링과 관련된 특정 프로세스에 대한 이해를 증진시키며, 기술 자체의 여러 세대를 거쳐 미래 보안 개선을 가져올 가능성이 높습니다.
3단계: 보안 정책 및 표준 초안 작성
단기적으로 특정 보안 프로토콜과 허용 가능한 기술을 의무화하는 것 외에도, 보안 정책과 표준 내에서 장기적인 프로세스 중심 접근법을 심화할 기회가 있습니다. 예를 들어, 제3자에 의한 연간 보안 취약성 평가를 요구하는 것이 일반적인 사례입니다. 이는 군사 분야에서 흔히 볼 수 있으며(예: 육군 FM 3-19.30.2), 금융 산업에서도 채택되었습니다(예: 23 NYCRR 500).
조직의 보안 정책 및 표준 초안은 제품 중심 및 프로세스 중심 요구 사항을 통합하는 데 초점을 맞추어야 하며, 이를 통해 학습 생태계 전반에 걸쳐 지속 가능한 보안을 구축하려는 시도를 가능하게 해야 합니다.
-
네트워크 보안
네트워크 강화는 학습자 데이터를 보호하기 위한 첫 번째 단계로, 여러 형태로 구현될 수 있습니다. 초기 취약성 테스트를 실행하고, 학습 생태계에 적합한 데이터 형식, 저장소, 전송 계층(예: xAPI 및 Kafka 표준에 의해 정의된)을 위한 Kerberos 기반 대안을 개발 및 배포하는 방식이 포함될 수 있습니다. 정상 사고 이론(normal-accident theory)을 적용하여 신뢰성이 높은 학습자 데이터 구조를 구축하는 잠재력은 특히 유망하며, 이는 네트워크와 이후 디바이스의 보안을 모두 강화할 수 있습니다.
-
디바이스 보안
디바이스 강화는 학습자 데이터와 관련된 파일을 읽고, 쓰고, 실행하려는 기기들의 분산된 특성으로 인해 과제를 제기할 가능성이 높습니다. 따라서 이 단계는 개별 기관 표준에 대한 체계적인 검토를 포함하며, 디바이스 연결성을 위한 실행 가능한 최소 표준을 추천하는 것을 목표로 합니다.
-
인간 요소 보안
사회적 보안 강화는 기술 중심의 인력에게 특히 어려운 과제입니다. 데이터 보안에서 인간 요소를 평가하고 개선하려면 인간 행동과 기술에 대한 이해를 통해 사이버 공격 벡터를 차단하는 행동을 정의하는 정책과 표준이 필요합니다. 기존 인력 보안 표준(예: 육군의 위협 인식 및 보고 프로그램(AR 381-12))을 신중히 검토하면, 분산 학습 아키텍처에서 인간 요소를 안전하게 보호하기 위한 모범 사례를 도출할 가능성이 높습니다.
4단계: 기대 관리 및 위험 관리 준비
어떤 보안 계획도 위험을 완전히 제거할 수는 없습니다. 특히 데이터를 집계, 저장, 처리하는 시스템에서는 기술 변화의 가속화로 인해 이러한 사실이 더욱 분명해집니다. 이 계획의 마지막 단계는 현재 보안 결과와 미래 기술 발전을 고려하여, 관련된 위험, 통제, 그리고 잔여 위험을 명시적으로 검토합니다.
4단계의 결과물은 3단계에서 작성된 정책과 표준의 수정 필요 시점을 평가하는 것을 포함해야 합니다. 주요 산출물은 다음을 포함합니다:
• 가정 목록: 분석 과정에서 사용된 가정을 명확히 정의
• 결과와 발견: 현재 보안 환경에서 확인된 사항의 요약
• 지표/경고: 이 계획에서 수행된 분석에 대한 방해적 영향을 예측하는 주요 지표와 경고 신호
이를 통해 조직은 변화하는 기술 환경 속에서도 지속적으로 보안 상태를 평가하고 조정할 수 있습니다.